2010
New Build of Datagenerator
31/12/10 11:34 Filed in: Datagenerator
Im releasing a new build of Datagenerator simply because there hasn’t been one for a while. Thats not to say it hasn’t undergone significant changes. Most of them are as a result of enhancements to support schema creation for swingbench. In particular is the introduction of Pre and Post generation scripts. These allow me to run a complete schema creation from within datagenerator. These scripts appear as top level items from within the tree (see below).
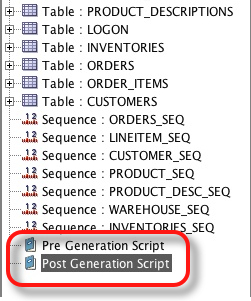
In the side panel you can now include scripts and parameters for the scripts.
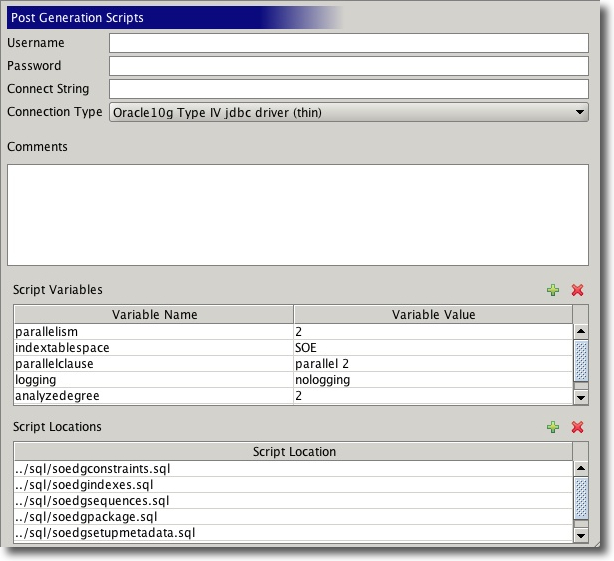
I’ve also included the script files used for generating the SH and SOE schemas used by swingbench. This should make it easier to understand what is going on and potentially create your own versions of the schemas.
In this release I’ve also improved the threading model and included one or two other performance enhancements....
In the next release I’m going to try and add support for for well know data items such as zip/post codes, NI numbers, Social Security etc.... as well as allowing users to plug their own data generators in.
You can download it from the usual place and as before leave comments below or via the comments page.
In the side panel you can now include scripts and parameters for the scripts.
I’ve also included the script files used for generating the SH and SOE schemas used by swingbench. This should make it easier to understand what is going on and potentially create your own versions of the schemas.
In this release I’ve also improved the threading model and included one or two other performance enhancements....
In the next release I’m going to try and add support for for well know data items such as zip/post codes, NI numbers, Social Security etc.... as well as allowing users to plug their own data generators in.
You can download it from the usual place and as before leave comments below or via the comments page.
Comments
Happy Christmas All...
24/12/10 18:54
Database Time Monitor
08/11/10 20:22
Fixes to CPUMonitor
06/11/10 14:24 Filed in: cpumonitor
New build of Swingbench
31/08/10 16:22 Filed in: Swingbench
After a bit of a delay Im releasing a new build of swingbench. It has a large number of fixes reflected in the difference in build numbers. Some of the changes include
The new report looks like this
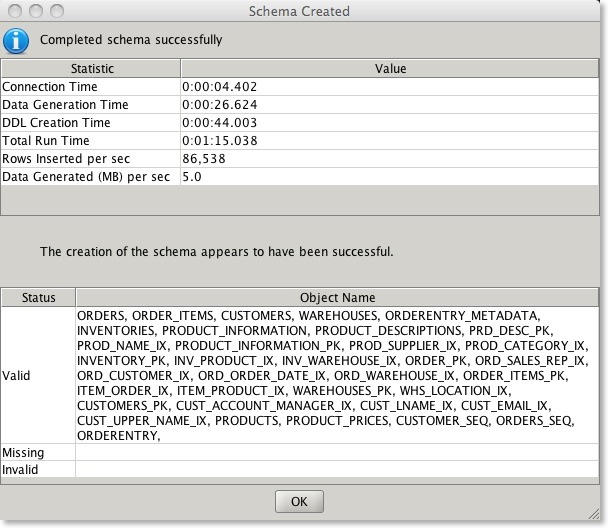
Im hoping it should make it easier to understand if a install worked correctly.
You can download the new build here. As usual let me know if it hangs together.
- A new report at the end of wizard driven install that details the speed of the install but also whether the objects that have been created are valid
- A fix to clusteroverview that prevented it starting
- A fix to the cpumonitor that prevented it from running in some instances
- Some icon changes
- Warning and error alerts are now fired inside of the wizard to highlight potential issues
- Fix that prevented install logs being saved
- Average response time can now be displayed in command line mode
- Removed the required to run the wizards in headless mode
- Fixed numerous UCP issues
- Many other fixes
The new report looks like this
Im hoping it should make it easier to understand if a install worked correctly.
You can download the new build here. As usual let me know if it hangs together.
TraceAnalyzer Update
07/06/10 21:42 Filed in: TraceAnalyzer
Minor update to swingbench
24/05/10 15:35 Filed in: Swingbench
CPUMonitor 0.2 just released
20/05/10 18:48 Filed in: cpumonitor
I’ve just released 0.2 of cpumonitor. Its got a few nice features in it.
# To disable tunneled clear text passwords, change to no here!PasswordAuthentication yes
You can download it from here as usual.
The following are a few screen shots of the mini mode and the max mode (default)
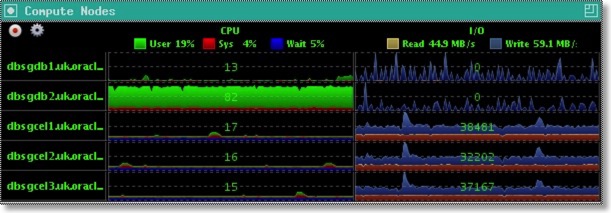
- Support for Solaris
- A Mini view (use the -md option on the command line)
- New charting engine (a bit punchier)
- Encrypted passwords in config file
- Fixes for rendering on Linux and Unix
- Reports errors for failed connections
# To disable tunneled clear text passwords, change to no here!PasswordAuthentication yes
You can download it from here as usual.
The following are a few screen shots of the mini mode and the max mode (default)
And another update to 2.4...
13/05/10 20:45 Filed in: Swingbench
Update to swingbench 2.4
15/04/10 21:05 Filed in: Swingbench
I’ve updated swingbench to build 628 which includes the following fixes
- Updates to the “order entry” benchmark
- Wizards now use user selected thread count
- Swingbench now correctly loads new config files from the menu
- Feedback on wizard builds (metrics such as MB/sec generated etc)
- Checks at start and end of wizard builds
- New benchmark run summaries
Large SOE builds... things to watch for
25/03/10 10:57 Filed in: Swingbench
A couple of things to watch for if you are building a large SOE schema. The first is temp space. I guess its obvious but if you are building a 1TB schema with 100GB+ tables the indexes are going to be pretty big as well. If you are creating big indexes you need plenty of TEMP. The number of schema’s I’ve looked at that haven’t had their indexes build is amazing. I guess this is partly my fault as well. I’ll include a start and end validation process in the next build. Should have done this before but I guess people weren’t building such big schema’s
As a guide line for a schema of size “x” I’d have at least “x/6” worth of temp space i.e. 1TB schema needs about 180GB of temp. You can resize it after the build to what ever you decide is appropriate.
As to what it should look like on completion... well something like this
SOE@//localhost/orcl > @tables;Tables======Table Rows Blocks Size Compression Indexes Partitions Analyzed-------------------- ---------- ----- ------ ----------- ------- ---------- ----------WAREHOUSES 1,000 60 1024k Disabled 2 0 < WeekORDERS 225,000 1,636 13M Disabled 5 0 < WeekINVENTORIES 924,859 10,996 87M Disabled 3 0 < WeekORDER_ITEMS 587,151 2,392 19M Disabled 3 0 < WeekPRODUCT_DESCRIPTIONS 1,000 60 1024k Disabled 2 0 < WeekLOGON 50,000 250 2M Disabled 0 0 < WeekPRODUCT_INFORMATION 1,000 60 1024k Disabled 3 0 < WeekCUSTOMERS 200,000 2,014 16M Disabled 5 0 < Week
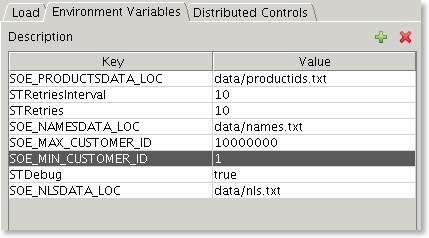
Another really important thing is to include the SOE_MIN_CUSTOMER_ID and SOE_MAX_CUSTOMER_ID in the environment variables within the config file. This will reduce the startup time of the benchmark. Follow the instructions below or edit the config file
Select the Environment Variables tab and press the button (you’ll need to do this for each environment variable).
button (you’ll need to do this for each environment variable).

Add two Enviroment variables
You can determine what thes values are by running a piece of SQL similar to this when logged into the SOE schema
SELECT /*+ PARALLEL(CUSTOMERS, 8) */ MIN(customer_id) SOE_MIN_CUSTOMER_ID, MAX(customer_id) SOE_MAX_CUSTOMER_ID FROM customers
After adding the variables you should end up with something that looks similar to this
As a guide line for a schema of size “x” I’d have at least “x/6” worth of temp space i.e. 1TB schema needs about 180GB of temp. You can resize it after the build to what ever you decide is appropriate.
As to what it should look like on completion... well something like this
SOE@//localhost/orcl > @tables;Tables======Table Rows Blocks Size Compression Indexes Partitions Analyzed-------------------- ---------- ----- ------ ----------- ------- ---------- ----------WAREHOUSES 1,000 60 1024k Disabled 2 0 < WeekORDERS 225,000 1,636 13M Disabled 5 0 < WeekINVENTORIES 924,859 10,996 87M Disabled 3 0 < WeekORDER_ITEMS 587,151 2,392 19M Disabled 3 0 < WeekPRODUCT_DESCRIPTIONS 1,000 60 1024k Disabled 2 0 < WeekLOGON 50,000 250 2M Disabled 0 0 < WeekPRODUCT_INFORMATION 1,000 60 1024k Disabled 3 0 < WeekCUSTOMERS 200,000 2,014 16M Disabled 5 0 < Week
Another really important thing is to include the SOE_MIN_CUSTOMER_ID and SOE_MAX_CUSTOMER_ID in the environment variables within the config file. This will reduce the startup time of the benchmark. Follow the instructions below or edit the config file
Select the Environment Variables tab and press the
Add two Enviroment variables
- SOE_MIN_CUSTOMER_ID : The value equals the smallest customer id in the data set, usually 1
- SOE_MAX_CUSTOMER_ID : The largerst customer id found in the data set
You can determine what thes values are by running a piece of SQL similar to this when logged into the SOE schema
SELECT /*+ PARALLEL(CUSTOMERS, 8) */ MIN(customer_id) SOE_MIN_CUSTOMER_ID, MAX(customer_id) SOE_MAX_CUSTOMER_ID FROM customers
After adding the variables you should end up with something that looks similar to this
Swingbench 2.4 Beta Released
23/03/10 20:03 Filed in: Swingbench
I may regret this but it all seems to hang togther so I’ve decided to release 2.4 of swingbench. It dosen’t look significantly different from 2.3 but it has enough changes to warrant a point change. These include....
The other big change is that I’’ve tried to standardise the benchmarks. You can now choose between 1GB,10GB,100GB or 1TB. The thing to watch out for is that this refers to the raw data size. The indexes add to this quite considerably. So a 1TB will require 3.2TB of disk space. The good news is that they are massively multi threaded now and so if you have the horse power (plenty of CPUs and IO) they should build relatively quickly (12 hours for a 1TB benchmark).
I’ve also updated the look of the overview graphs to make them a little punchier... I’ll be improving them still further shortly.
So now the stuff that’s a little broken....
- New SH wizard
- New highly threaded benchmark builds for the OE and SH benchmarks
- New standard sizings for SOE and SH (1GB,10GB,100GB,1TB)
- Improved scalability of the SOE benchmark
- Oracle UCP connections
- New CPU monitor architecture (uses ssh instead of agent)
- Update look and feel on Overview charts (more coming)
- Configuration free install (Simply ensure Java is your path)
The other big change is that I’’ve tried to standardise the benchmarks. You can now choose between 1GB,10GB,100GB or 1TB. The thing to watch out for is that this refers to the raw data size. The indexes add to this quite considerably. So a 1TB will require 3.2TB of disk space. The good news is that they are massively multi threaded now and so if you have the horse power (plenty of CPUs and IO) they should build relatively quickly (12 hours for a 1TB benchmark).
I’ve also updated the look of the overview graphs to make them a little punchier... I’ll be improving them still further shortly.
So now the stuff that’s a little broken....
- Charbench’s interactive mode seems to have cracked under the weight of all the updates. I have a fix for it but it requires a 1.6 JVM and Im trying to figure out if I can port it to 1.5. In the mean time you’ll have to use timers (-rt option) until I have a workable fix.
- Backgrounding tasks seems to be a little broken as well... I hope to have a fix for this shortly.
- An end of run benchmark report. I’ve got it sort of working but it’s a little awkward looking.
- Update to coodinator controls...
- AIX cpu monitoring... I have the code. It just needs testing.
Scalability fix for orderentry benchmark
16/03/10 09:57
I’ve been doing some testing lately on some pretty fast servers of late, in particular Exadata V2. This has resulted in issues with the swingbench “SOE” benchmark that I hadn’t seen before such as data and index block contention and even some deadlocks (yes shame on me). So I took a look at the way the code worked and have updated it to use more efficient (and arguably more up to date) approaches to the same processes. The code still does the same number of selects,inserts and updates but removes some silly none scalable operations as well. This code will ship in swinbench 2.4 (yes I’ve decided to update to 2.4.... there’s a lot of changes) but I thought some people might find the new V1.1 version of the benchmark useful today so Im making it available on the downloads page. It should just be a simple update to the schema... i.e.
$> sqlplus soe/soe @soedgpackage.sql
Whilst this will fix a large number of problems you may need to reverse key a few indexes as well... (This will be part of the full installation in 2.4)
Let me know how you get on....
$> sqlplus soe/soe @soedgpackage.sql
Whilst this will fix a large number of problems you may need to reverse key a few indexes as well... (This will be part of the full installation in 2.4)
Let me know how you get on....
Why hasn't here been an update lately?
22/02/10 17:20 Filed in: General
Best laid plans and all that.... I had hoped to release the new 2.4 build this week but work is insane at present and so I haven’t had time to do the necessary testing. It’s a pain I know. I have promised people releases a lot lately but work just gets busier and busier and since I can really only do swingbench development in my spare time Im struggling to keep up.
Im hoping things will die down in the next few weeks and so I should be able to get it done then. So if I don’t reply to emails it’s not being rude its just that I don’t have time... I’ll make it up I promise.
Im hoping things will die down in the next few weeks and so I should be able to get it done then. So if I don’t reply to emails it’s not being rude its just that I don’t have time... I’ll make it up I promise.