2008
Datagenerator Fix
19/12/08 11:20 Filed in: Swingbench
I’ve updated datagenerator to fix a few bugs, improve the perfromance and give a little more feedback when running from the commandline. You can find it in the usual place.
Comments
Broken clusteroverview in later builds
17/10/08 17:43 Filed in: Swingbench
It appears that I’ve broken some of the functionality in clusteroverview in the latest builds... In particular the scalability portion and the reporting of CPU.
I’ll fix this and get a new build out ASAP.
Apologies
Dom
I’ll fix this and get a new build out ASAP.
Apologies
Dom
Flash version of the screencast now available
05/10/08 15:49 Filed in: Swingbench
I’ve just upload a flash version of the walkthrough screencast. Hope this helps the Linux users.
New builds of swingbench and datagenerator
01/10/08 16:38 Filed in: Swingbench
New Swingbench Screencast
01/10/08 16:36 Filed in: Swingbench
Minor Change to the look and feel of the web site
01/10/08 16:05 Filed in: General
I’ve taken the oppertunity to update the look and feel of the web site. Hopefully its made it a little cleaner and easier to navigate. Let me know if you think I should go back to the old style. I’ll slowly update some of the content too.
Large scale data sets for "SOE" and "SH"
02/09/08 22:16
I’ve added some new pages describing how to build large scale “SOE” and “SH” schemas. I’ve tested them both to 500GB in size and will create larger scale versions as soon as I can borrow hardware to test them at multi terabyte levels. If you’re interested in giving it ago let me know via the comments page and I can try and assist. You can find the the instructions on how to do create 100GB+ schemas for “SOE” here and the how to create 100GB+ “SH” schemas here
Update : I noticed that the scripts for SH use compression by default. This can slow down a load. and make the expected upload much smaller. I’ll upload a new build shortly that fixes this and afew other issues.
Update : I noticed that the scripts for SH use compression by default. This can slow down a load. and make the expected upload much smaller. I’ll upload a new build shortly that fixes this and afew other issues.
Datagenerator 0.4
02/09/08 20:09 Filed in: Swingbench
I've uploaded a new build of datagenerator. New features include
The new build can be downloaded here
I’ve also updated the install, and added some additional walk throughs (in the swingbench section)
Lets go through some of the new features in a little more detail.
You can now include indexes and sequences inside of a datagenerator definition
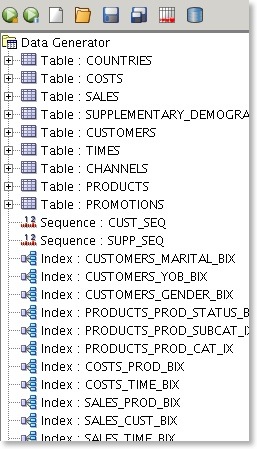
This makes it easy to build an entire schema for a benchmark run removing the need to run additional scripts afterwards. Currently I don't support their reverse engineering but that will come.
Previously it was possible to specify multiple threads for a datageneration run but each table was allocated a single thread. In this version a user can soft partition a table and hence break the build into smaller units which can each have a thread allocated to them.
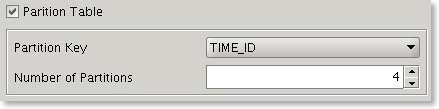
This means that if you have a 32 CPU server you'll be able to build a 10 billion row table much faster if you soft partition the table into 32 units and allocate 32 threads for the build. The partition key can be either a date or number. This is also useful to avoid resource contention when inserting data into a partitioned table.
Its now possible to run the entire data generation to file or database from the command line. These include
[dgiles@macbook bin]$ ./datagenerator -h
usage: parameters:
-async perform async commits
-bs batch size of inserts (defaults to 50)
-c specify config file
-cl use command line interface
-commit number of inserts between commits
-cs connectring for database insertion
-d output directory (defaults to "data")
-db write data direct to database
-ddl just generate the ddl to be used
-debug turn on debug information
-dt driver type (oci|thin)
-f write data to file
-g use graphical user interface
-h,--help print this message
-ni don't create any indexes after data creation
-nodrop don't drop tables if they exist
-p password for database insertion
-s run silent
-scale mulitiplier for default config
-tc number of generation threads (defaults to 2)
-u username for database insertion
-z compress the results file
The config files for the soe and sh schema are now by default configured for a 1GB build. These can be scaled up by using the -scale option. To build a 100GB sh schema the following command can be used.
./datagenerator -c sh.xml -cl -scale 100
This functionality is supplemented by a new flag on a table definition.
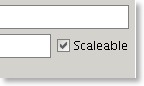
Only tables with this flag enabled will be scaled up.
It is now possible to use the row count of a table as the maximum value of a number generator. This is useful when scaling up/down a datageneration and maintaining data coverage and referential integrity.

As the number of rows in the referenced table increase so does the the maximum value of the data generator.
This build supports the use of asynchronous commits. This results in performance increases of about 10-30% when this option is enabled. I’ve also undergone several database
It is sometimes useful to only create the DDL that will used to create tables and indexes.

The files that are created can be edited and modified to include additional information such as storage definitions.
- Support for indexes and sequences
- New command line options
- Better multi threading support
- New scaleable data builds
- Number generators can reference row counts from other tables
- Better database performance
- Ability to generate only the DDL of a schema
- Numerous bug fixes
The new build can be downloaded here
I’ve also updated the install, and added some additional walk throughs (in the swingbench section)
Lets go through some of the new features in a little more detail.
Indexes and Sequences
You can now include indexes and sequences inside of a datagenerator definition
This makes it easy to build an entire schema for a benchmark run removing the need to run additional scripts afterwards. Currently I don't support their reverse engineering but that will come.
Better multithreading support
Previously it was possible to specify multiple threads for a datageneration run but each table was allocated a single thread. In this version a user can soft partition a table and hence break the build into smaller units which can each have a thread allocated to them.
This means that if you have a 32 CPU server you'll be able to build a 10 billion row table much faster if you soft partition the table into 32 units and allocate 32 threads for the build. The partition key can be either a date or number. This is also useful to avoid resource contention when inserting data into a partitioned table.
New command line options
Its now possible to run the entire data generation to file or database from the command line. These include
[dgiles@macbook bin]$ ./datagenerator -h
usage: parameters:
-async perform async commits
-bs
-c
-cl use command line interface
-commit
-cs connectring for database insertion
-d
-db write data direct to database
-ddl just generate the ddl to be used
-debug turn on debug information
-dt driver type (oci|thin)
-f write data to file
-g use graphical user interface
-h,--help print this message
-ni don't create any indexes after data creation
-nodrop don't drop tables if they exist
-p password for database insertion
-s run silent
-scale
-tc number of generation threads (defaults to 2)
-u username for database insertion
-z compress the results file
Scaleable data builds
The config files for the soe and sh schema are now by default configured for a 1GB build. These can be scaled up by using the -scale option. To build a 100GB sh schema the following command can be used.
./datagenerator -c sh.xml -cl -scale 100
This functionality is supplemented by a new flag on a table definition.
Only tables with this flag enabled will be scaled up.
Referenceable row counts
It is now possible to use the row count of a table as the maximum value of a number generator. This is useful when scaling up/down a datageneration and maintaining data coverage and referential integrity.
As the number of rows in the referenced table increase so does the the maximum value of the data generator.
Better database performance
This build supports the use of asynchronous commits. This results in performance increases of about 10-30% when this option is enabled. I’ve also undergone several database
Generate only DDL
It is sometimes useful to only create the DDL that will used to create tables and indexes.
The files that are created can be edited and modified to include additional information such as storage definitions.
Timing groups of SQL operations
02/09/08 10:47 Filed in: Oracle
Some times I feel like I’ve missed out on a whole chunk on functionality in Oracle products. One little nugget is the “timing” function in SQL*Plus. This allows you to time groups of operations.
Obviously turning on is achieved with the “set timing on” operation. i.e
SQL > set timing on
SQL > select count(1) from all_objects;
COUNT(1)
----------
68653
Elapsed: 00:00:03.95
SQL>
Which is great but what if want to time mulitiple operations. Use the timing function and simply give the timer a name, in this case statement timer.
SQL> timing start statement_timer
SQL> select count(1) from all_objects;
COUNT(1)
----------
68653
SYS@orcl > /
COUNT(1)
----------
68653
SQL> timing show statement_timer;
timing for: statement_timer
Elapsed: 00:00:30.85
SQL>
Which times anything that went on in between the timer starting and finishing. In this case also my typing of the commands. Its a fantastic utility for timing stages in a batch job including call outs to os operations.
Obviously turning on is achieved with the “set timing on” operation. i.e
SQL > set timing on
SQL > select count(1) from all_objects;
COUNT(1)
----------
68653
Elapsed: 00:00:03.95
SQL>
Which is great but what if want to time mulitiple operations. Use the timing function and simply give the timer a name, in this case statement timer.
SQL> timing start statement_timer
SQL> select count(1) from all_objects;
COUNT(1)
----------
68653
SYS@orcl > /
COUNT(1)
----------
68653
SQL> timing show statement_timer;
timing for: statement_timer
Elapsed: 00:00:30.85
SQL>
Which times anything that went on in between the timer starting and finishing. In this case also my typing of the commands. Its a fantastic utility for timing stages in a batch job including call outs to os operations.
New build and fixes in swingbench
22/07/08 12:29 Filed in: Swingbench
On the subject of ISCSI and udev
09/06/08 08:33 Filed in: Linux
Ok so I admit I haven't been updating the web site recently. Im pretty much overrun with work (and I took a weeks holiday) so updates to swingbench have had to be put on hold. That said I haven't been idle. I've been setting up a RAC cluster under Oracle Virtual Server (NOTE : This is not currently supported).
The environrment is build using 3 Dell Lattitude notebooks and a 1Gb Netgear switch. I've installed one notebook with OpenFiler as the storage server and two additional notebooks with Oracle Virtual Server. (NOTE : this really isn't advised as a production implementation ). I've used the Oracle Enterprise Template to create the Linux Servers running Oracle11g. It was pretty straight sailing with a few notable exceptions
). I've used the Oracle Enterprise Template to create the Linux Servers running Oracle11g. It was pretty straight sailing with a few notable exceptions
The environrment is build using 3 Dell Lattitude notebooks and a 1Gb Netgear switch. I've installed one notebook with OpenFiler as the storage server and two additional notebooks with Oracle Virtual Server. (NOTE : this really isn't advised as a production implementation
- Many of the shipping templates benefit (and some require) the activation of hardware acceleration. This can be done via the BIOS and will make a big difference to performance in most circumstances.
- UDev and ISCSI. This sadly caused me real problems and Im still not sure why. I was under the impression that the devices presented from the Openfiler (the ISCSI Target) would have consistent ID's. Now I've no reason to make this claim it just seemed like a sensible thing to do. I originally used the ENV{ID} to uniquely identify the devices and create persistent links to the disks. However subsequent reboots showed these to change. We eventually ended up using a rule similar to the folowing
- We also encountered some library issues (rpm), Some of the openfiler devices couldn't be seen however upgrading to the very latest initiator libraries solved the problem (At the time of writing this iscsi-initiator-utils-6.2.0.868-0.7.el5).
Minor update to datagenerator
29/03/08 11:01 Filed in: Swingbench
Just a minor update to datagenerator to fix some scripts and config files. There's also a few fixes to the code.
Swingbench with AWR support
25/03/08 21:25 Filed in: Swingbench
Im uploading a new build of swingbench that includes support for performing AWR snaps at the start and end of of a benchmark run.
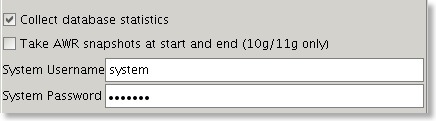
This is a common request and automates a task that a lot of people do. I've also included a new section in the stats that are generated which lists the top 10 (11 to be exact if you include CPU) wait events for a run if you choose to collect database statistics.
I've had a lot of requests about 9i support in swingbench which I appear to have broken. Can you let me know if you still think this is important (I guess its implied by the requests I've had). I need to know whether to focus on this of finish the 2.3 doc.
I'd also appreciate if you could let me know if the wait events I report are in line with the stats you get from ARW... if they're not its down to me not AWR.
Thanks...
This is a common request and automates a task that a lot of people do. I've also included a new section in the stats that are generated which lists the top 10 (11 to be exact if you include CPU) wait events for a run if you choose to collect database statistics.
I've had a lot of requests about 9i support in swingbench which I appear to have broken. Can you let me know if you still think this is important (I guess its implied by the requests I've had). I need to know whether to focus on this of finish the 2.3 doc.
I'd also appreciate if you could let me know if the wait events I report are in line with the stats you get from ARW... if they're not its down to me not AWR.
Thanks...
New build of swingbench 2.3 (Build 370)
06/03/08 14:57
New build of swingbench 2.3
12/02/08 12:22 Filed in: Swingbench
I know things have been a little slow of late in terms of the releases of code but I've just had too much on both at work and at home. The good news is that I've found time to squeeze in a new build of swingbench. This has a number of bug fixes in and the following new functionality.
I've also included a walk through of how to set up clusteroverview in 2.3 with the new GroupID functionality, you can find it here.
Any problems report them through the usual channels...
- Clusteroverview now uses the groupID attribute to determine members of a load generation group. This provides a lot more flexibility for clusteroverview to be used to test technologies such as Oracle Dataguard
- The output from the command line option -v can now be directed to a named file with the -vo option
I've also included a walk through of how to set up clusteroverview in 2.3 with the new GroupID functionality, you can find it here.
Any problems report them through the usual channels...