Datagenerator 0.4
02/09/08 20:09 Filed in: Swingbench
I've uploaded a new build of datagenerator. New features include
The new build can be downloaded here
I’ve also updated the install, and added some additional walk throughs (in the swingbench section)
Lets go through some of the new features in a little more detail.
You can now include indexes and sequences inside of a datagenerator definition
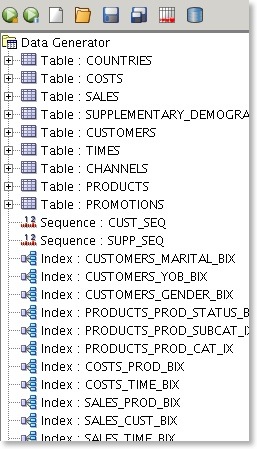
This makes it easy to build an entire schema for a benchmark run removing the need to run additional scripts afterwards. Currently I don't support their reverse engineering but that will come.
Previously it was possible to specify multiple threads for a datageneration run but each table was allocated a single thread. In this version a user can soft partition a table and hence break the build into smaller units which can each have a thread allocated to them.
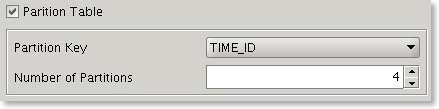
This means that if you have a 32 CPU server you'll be able to build a 10 billion row table much faster if you soft partition the table into 32 units and allocate 32 threads for the build. The partition key can be either a date or number. This is also useful to avoid resource contention when inserting data into a partitioned table.
Its now possible to run the entire data generation to file or database from the command line. These include
[dgiles@macbook bin]$ ./datagenerator -h
usage: parameters:
-async perform async commits
-bs batch size of inserts (defaults to 50)
-c specify config file
-cl use command line interface
-commit number of inserts between commits
-cs connectring for database insertion
-d output directory (defaults to "data")
-db write data direct to database
-ddl just generate the ddl to be used
-debug turn on debug information
-dt driver type (oci|thin)
-f write data to file
-g use graphical user interface
-h,--help print this message
-ni don't create any indexes after data creation
-nodrop don't drop tables if they exist
-p password for database insertion
-s run silent
-scale mulitiplier for default config
-tc number of generation threads (defaults to 2)
-u username for database insertion
-z compress the results file
The config files for the soe and sh schema are now by default configured for a 1GB build. These can be scaled up by using the -scale option. To build a 100GB sh schema the following command can be used.
./datagenerator -c sh.xml -cl -scale 100
This functionality is supplemented by a new flag on a table definition.
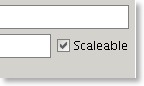
Only tables with this flag enabled will be scaled up.
It is now possible to use the row count of a table as the maximum value of a number generator. This is useful when scaling up/down a datageneration and maintaining data coverage and referential integrity.

As the number of rows in the referenced table increase so does the the maximum value of the data generator.
This build supports the use of asynchronous commits. This results in performance increases of about 10-30% when this option is enabled. I’ve also undergone several database
It is sometimes useful to only create the DDL that will used to create tables and indexes.

The files that are created can be edited and modified to include additional information such as storage definitions.
- Support for indexes and sequences
- New command line options
- Better multi threading support
- New scaleable data builds
- Number generators can reference row counts from other tables
- Better database performance
- Ability to generate only the DDL of a schema
- Numerous bug fixes
The new build can be downloaded here
I’ve also updated the install, and added some additional walk throughs (in the swingbench section)
Lets go through some of the new features in a little more detail.
Indexes and Sequences
You can now include indexes and sequences inside of a datagenerator definition
This makes it easy to build an entire schema for a benchmark run removing the need to run additional scripts afterwards. Currently I don't support their reverse engineering but that will come.
Better multithreading support
Previously it was possible to specify multiple threads for a datageneration run but each table was allocated a single thread. In this version a user can soft partition a table and hence break the build into smaller units which can each have a thread allocated to them.
This means that if you have a 32 CPU server you'll be able to build a 10 billion row table much faster if you soft partition the table into 32 units and allocate 32 threads for the build. The partition key can be either a date or number. This is also useful to avoid resource contention when inserting data into a partitioned table.
New command line options
Its now possible to run the entire data generation to file or database from the command line. These include
[dgiles@macbook bin]$ ./datagenerator -h
usage: parameters:
-async perform async commits
-bs
-c
-cl use command line interface
-commit
-cs connectring for database insertion
-d
-db write data direct to database
-ddl just generate the ddl to be used
-debug turn on debug information
-dt driver type (oci|thin)
-f write data to file
-g use graphical user interface
-h,--help print this message
-ni don't create any indexes after data creation
-nodrop don't drop tables if they exist
-p password for database insertion
-s run silent
-scale
-tc number of generation threads (defaults to 2)
-u username for database insertion
-z compress the results file
Scaleable data builds
The config files for the soe and sh schema are now by default configured for a 1GB build. These can be scaled up by using the -scale option. To build a 100GB sh schema the following command can be used.
./datagenerator -c sh.xml -cl -scale 100
This functionality is supplemented by a new flag on a table definition.
Only tables with this flag enabled will be scaled up.
Referenceable row counts
It is now possible to use the row count of a table as the maximum value of a number generator. This is useful when scaling up/down a datageneration and maintaining data coverage and referential integrity.
As the number of rows in the referenced table increase so does the the maximum value of the data generator.
Better database performance
This build supports the use of asynchronous commits. This results in performance increases of about 10-30% when this option is enabled. I’ve also undergone several database
Generate only DDL
It is sometimes useful to only create the DDL that will used to create tables and indexes.
The files that are created can be edited and modified to include additional information such as storage definitions.
blog comments powered by Disqus