swingbench
Testing a new build of swingbench
05/01/16 09:09
I haven't released any updates to swingbench in a while and the reason was that I encountered a difficult to debug "concurrent modification" issue. Normally these are pretty straight forward to find if you are regularly modifying the code. However that's not how I work. I only modify the swingbench code base when I find the time which is generally when something else is cancelled at short notice… Or there's a massive issue with a release.
The problem I had this time around was I made a "quick fix" a couple of years ago to a section of the code that creates the various snapshots of data during a timed run. I always meant to come back and fix this "quick fix" when I found the time… Anyway, fast forward to October last year and I added some code that created "percentiles" for reporting for simple and full stats collection. This lead to some behaviour on the stats collection that created a near impossible to debug "concurrent modification exception". The only solution was to painstakingly go through all of the threaded code to find the issue. It turns out that the "quick fix" I made created a sublist of a section of the data structure as a "view" instead of a new copy. An amateurish mistake to make but I guess not uncommon if you maintain the code in the way I do….
So what I'm looking for is some volunteers to check that the code works as expected.
You can find the new build of the code here. You'll need Java 8 on the machine you're installing it on.
The steps needed to test the problem code are…
Alternatively do this in charbench with a command like
This should generate a results file in the directory you started it from.
Appreciate the time and effort for helping me out…
Alongside the fix to this difficult build I've also included the additional functionality in this build
The problem I had this time around was I made a "quick fix" a couple of years ago to a section of the code that creates the various snapshots of data during a timed run. I always meant to come back and fix this "quick fix" when I found the time… Anyway, fast forward to October last year and I added some code that created "percentiles" for reporting for simple and full stats collection. This lead to some behaviour on the stats collection that created a near impossible to debug "concurrent modification exception". The only solution was to painstakingly go through all of the threaded code to find the issue. It turns out that the "quick fix" I made created a sublist of a section of the data structure as a "view" instead of a new copy. An amateurish mistake to make but I guess not uncommon if you maintain the code in the way I do….
So what I'm looking for is some volunteers to check that the code works as expected.
You can find the new build of the code here. You'll need Java 8 on the machine you're installing it on.
The steps needed to test the problem code are…
- Unzip the swingbench zip file (swingbenchtest.zip)
- Change into the bin directory (on Linux/Unix) or winbin directory (on windows)
- Create a new swingbench schema using oewizard or shwizard. This will walk you through the install against your database (11.2 or 12.1)
- Start up swingbench or charbench…
- Set and test the connection to the database that you ran oewizard against
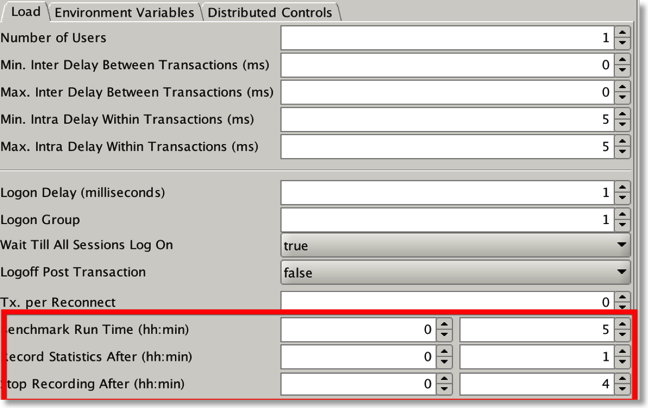
- Set the Benchmark run time to a value i.e. 10mins,
- Set the start record statistics to a value i.e. 2mins
- Set the stop record statistics to a value i.e. 8mins
- Start the benchmark run
- When it finished check that stats/xml has been created in the output tab.
Alternatively do this in charbench with a command like
./charbench -cs //oracleserver/orcl -u soe -p soe -uc 100 -rt 0:10 -bs 0:02 -be 0:08
This should generate a results file in the directory you started it from.
Appreciate the time and effort for helping me out…
Alongside the fix to this difficult build I've also included the additional functionality in this build
- Percentiles are now created for both "simple" and "full" stats collection
- You can now specify "rt", "bs" and "be" in fractions of a second i.e. 0:00.30 (30 seconds). Previously is had a granularity of minutes
- An initial JSON in the database benchmark framework has been created.
Comments
Swingbench Util... Going Big...
07/03/15 16:55 Filed in: Swingbench
I’ve added a utility to swingbench that perhaps I should’ve done a long time ago. The idea behind it is that it enables you to validate, fix or duplicate the data created by the wizards. I’m often contacted by people asking me how to fix an install of “Order Entry” or the “Sales History” benchmark after they’ve been running for many hours only to find they run out of temp space for the index creation. I’m also asked how they can make a really big “Sales History” schema when they only have relatively limited compute power and to create a multi terabyte data set might take days. Well the good news is that now, most of this should be relatively easy. The solution is a little program called “subtil” and you can find it in your bin or win bin directory.
Currently sbutil is command line only and requires a number of parameters to get it to do anything useful. The main parameters are
will duplicate the data in the soe schema but will first sort the seed data. You should see output similar to this
The following example validates a schema to ensure that the tables and indexes inside a schema are all present and valid
The output of the command will look similar to to this
The next command lists the tables in a schema
To drop the indexes in a schema use the following command
To recreate the indexes in a schema use the following command
You can download the new version of the software here.
Currently sbutil is command line only and requires a number of parameters to get it to do anything useful. The main parameters are
- “-dup” indicates the number of times you want data to be duplicated within the schema. Valid values are 1 to n. Data is copied and new primary keys/foreign keys generated where necessary. It’s recommended that you first increase/extend the tablespace before beginning the duplication. The duplication process will also rebuild the indexes and update the metadata table unless you specifically ask it not to with the “-nic” option. This is useful if you know you’ll be reduplicated the data again at a later stage.
- “-val” validates the tables and indexes in the specified schema. It will list any missing indexes or invalid code.
- “-stats” will create/recreate statistics for the indicated schema
- “-delstats” will delete all of the statistics for the indicated schema
- “-tables” will list all of the tables and row counts (based on database statistics) for the indicated schema
- “-di” will drop all of the indexes for the indicated schema
- “-ci” will recreate all of the indexes for the indicated schema
- “-u” : required. the username of the schema
- “-p” : required. the password of the schema
- “-cs” : required. the connect string of the schema. Some examples might be “localhost:1521:db12c”, “//oracleserver/soe” “//linuxserver:1526/orcl” etc.
- “-parallel” the level of parallelism to use to perform operations. Valid values are 1 to n.
- “-sort” sort the seed data before duplicating it.
- “-nic” don’t create indexes or constraints at the end of a duplication
- “-ac” convert the “main” tables to advanced compression
- “-hcc” convert the main tables to Hybrid Columnar Compression
- “-soe” : required. the target schema will be “Order Entry”
- “-sh” : required. the target schema will be “Sales History”
sbutil -u soe -p soe -cs //oracleserver/soe -dup 2 -parallel 32 -sort -soe
will duplicate the data in the soe schema but will first sort the seed data. You should see output similar to this
Getting table Info Got table information. Completed in : 0:00:26.927 Dropping Indexes Dropped Indexes. Completed in : 0:00:05.198 Creating copies of tables Created copies of tables. Completed in : 0:00:00.452 Begining data duplication Completed Iteration 2. Completed in : 0:00:32.138 Creating Constraints Created Constraints. Completed in : 0:04:39.056 Creating Indexes Created Indexes. Completed in : 0:02:52.198 Updating Metadata and Recompiling Code Updated Metadata. Completed in : 0:00:02.032 Determining New Row Counts Got New Row Counts. Completed in : 0:00:05.606 Completed Data Duplication in 0 hour(s) 9 minute(s) 44 second(s) 964 millisecond(s) ---------------------------------------------------------------------------------------------------------- |Table Name | Original Row Count| Original Size| New Row Count| New Size| ---------------------------------------------------------------------------------------------------------- |ORDER_ITEMS | 172,605,912| 11.7 GB| 345,211,824| 23.2 GB| |CUSTOMERS | 40,149,958| 5.5 GB| 80,299,916| 10.9 GB| |CARD_DETAILS | 60,149,958| 3.4 GB| 120,299,916| 6.8 GB| |ORDERS | 57,587,049| 6.7 GB| 115,174,098| 13.3 GB| |ADDRESSES | 60,174,782| 5.7 GB| 120,349,564| 11.4 GB| ----------------------------------------------------------------------------------------------------------
The following example validates a schema to ensure that the tables and indexes inside a schema are all present and valid
./sbutil -u soe -p soe -cs //ed2xcomp01/DOMS -soe -val
The output of the command will look similar to to this
The Order Entry Schema appears to be valid. -------------------------------------------------- |Object Type | Valid| Invalid| Missing| -------------------------------------------------- |Table | 10| 0| 0| |Index | 26| 0| 0| |Sequence | 5| 0| 0| |View | 2| 0| 0| |Code | 1| 0| 0| --------------------------------------------------
The next command lists the tables in a schema
./sbutil -u soe -p soe -cs //ed2xcomp01/DOMS -soe -tables Order Entry Schemas Tables ---------------------------------------------------------------------------------------------------------------------- |Table Name | Rows| Blocks| Size| Compressed?| Partitioned?| ---------------------------------------------------------------------------------------------------------------------- |ORDER_ITEMS | 17,157,056| 152,488| 11.6GB| | Yes| |ORDERS | 5,719,160| 87,691| 6.7GB| | Yes| |ADDRESSES | 6,000,000| 75,229| 5.7GB| | Yes| |CUSTOMERS | 4,000,000| 72,637| 5.5GB| | Yes| |CARD_DETAILS | 6,000,000| 44,960| 3.4GB| | Yes| |LOGON | 0| 0| 101.0MB| | Yes| |INVENTORIES | 0| 0| 87.0MB| Disabled| No| |PRODUCT_DESCRIPTIONS | 0| 0| 1024KB| Disabled| No| |WAREHOUSES | 0| 0| 1024KB| Disabled| No| |PRODUCT_INFORMATION | 0| 0| 1024KB| Disabled| No| |ORDERENTRY_METADATA | 0| 0| 1024KB| Disabled| No| ----------------------------------------------------------------------------------------------------------------------
To drop the indexes in a schema use the following command
./sbutil -u sh -p sh -cs //oracle12c2/soe -sh -di Dropping Indexes Dropped Indexes. Completed in : 0:00:00.925
To recreate the indexes in a schema use the following command
./sbutil -u sh -p sh -cs //oracle12c2/soe -sh -ci Creating Partitioned Indexes and Constraints Created Indexes and Constraints. Completed in : 0:00:03.395
You can download the new version of the software here.
New build of swingbench with improved stats
13/07/14 09:23 Filed in: Swingbench
I’ve uploaded a new build of swingbench that fixes a number of bugs but also improves on the stats being produced.
One problem with using averages when analysing results is that they hide a multitude of evils. This is particularly true for response times where there are likely to be big skews hidden if just the average is considered. You can see this in the chart below where response times are mapped into 100 buckets. The response time range from 2 to 6274 milliseconds. The average is 257ms.
It might be that in many instances the average is adequate for your needs but if your interested in the spread of results and the impact metrics like user counts, IO, memory etc have on the responsiveness of your system it might also be useful to model the spread of response so you can look for outliers.
In the latest build of swingbench when you now specify full stats collection you end up with a more complete set of results as shown below
257.86816475601097 2 6274 117.80819459762236 276.6820016426486 76552.9300329826 7.96379726468569 1.7844202125604447 14 25 43 87 170 257 354 466 636 21495, 5260, 4380, 4084, 3929, 3798, 3266, 2756, 2303, 1801, 1465, 1138, 889, 632, 499, 381, 259, 201, 140, 105, 102, 55, 43, 21, 21, 21, 17, 12, 9, 4, 5, 3, 12, 1, 6, 3, 7, 5, 1, 1, 6, 1, 2, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 59142 0 0
I’ve included a complete set of percentiles and some additional metrics for consideration (variance, Kurtosis, Skewness, Geometric Mean). Over the coming weeks I’ll be attempting to process a results file into a more useful document.
You can enable stats collection in the UI from the preferences tab i.e.
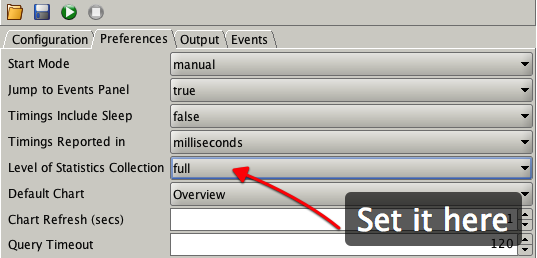
You can also set it from the command line. i.e.
./charbench -bg -s -stats full -rt 0:04 -cs //oracle12c2/orcl -a -uc 25 -com "Test of full stats collection" -intermin 2 -intermax 2 -bs 0:01 -be 0:04 &
One thing to watch out for is that you may need to change the metric that transactions are measure in i.e. from milliseconds to microseconds to model a better spread of response times.
Along side the improvements to stats I’ve also fixed the following
You can download the code front he usual place here
One problem with using averages when analysing results is that they hide a multitude of evils. This is particularly true for response times where there are likely to be big skews hidden if just the average is considered. You can see this in the chart below where response times are mapped into 100 buckets. The response time range from 2 to 6274 milliseconds. The average is 257ms.
It might be that in many instances the average is adequate for your needs but if your interested in the spread of results and the impact metrics like user counts, IO, memory etc have on the responsiveness of your system it might also be useful to model the spread of response so you can look for outliers.
In the latest build of swingbench when you now specify full stats collection you end up with a more complete set of results as shown below
I’ve included a complete set of percentiles and some additional metrics for consideration (variance, Kurtosis, Skewness, Geometric Mean). Over the coming weeks I’ll be attempting to process a results file into a more useful document.
You can enable stats collection in the UI from the preferences tab i.e.
You can also set it from the command line. i.e.
./charbench -bg -s -stats full -rt 0:04 -cs //oracle12c2/orcl -a -uc 25 -com "Test of full stats collection" -intermin 2 -intermax 2 -bs 0:01 -be 0:04 &
One thing to watch out for is that you may need to change the metric that transactions are measure in i.e. from milliseconds to microseconds to model a better spread of response times.
Along side the improvements to stats I’ve also fixed the following
- Fixed windowed stats collection (-be -bs) and full stats (-stats full) working together
- Fixed the -bg (background) option so it works on Solaris
- Numerous stability fixes
You can download the code front he usual place here
Fixes come in thick and fast...
20/11/13 14:15 Filed in: Swingbench
Yet another fix and some more minor UI changes.
In fixing some code I regressed some basic functionality. In the last build if you restarted a benchmark from within the swingbench and minibench GUI it gave you an error and you had to restart swingbench to get it going again. This is now fixed in this new build.
I also took the time to add some functionality to enable you to specify Inter and Intra sleep times. You can do this in the “Load” tab as shown below
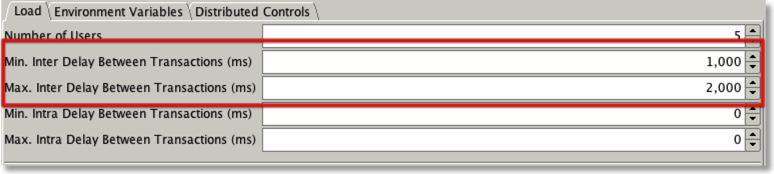
It gives me the opportunity to explain the difference between inter and intra sleep times. As the name implies intra sleep times occur “inside” of a transaction. Inter sleep times occur between transactions. Many of the transactions inside of the swingbench “SOE” have sleep times between DML operations (select, insert, update). In some situations this better emulates what happens in some legacy form based systems, this is what is controlled by intra sleep times. However most systems these days tend to utilise web based front ends where DML operations tend to be fired as a single operation when the user submits a form. This approach results in a more scalable architecture with fewer locks being held and for shorter periods of time. Hopefully the following diagram will explain the differences in a clearer fashion.
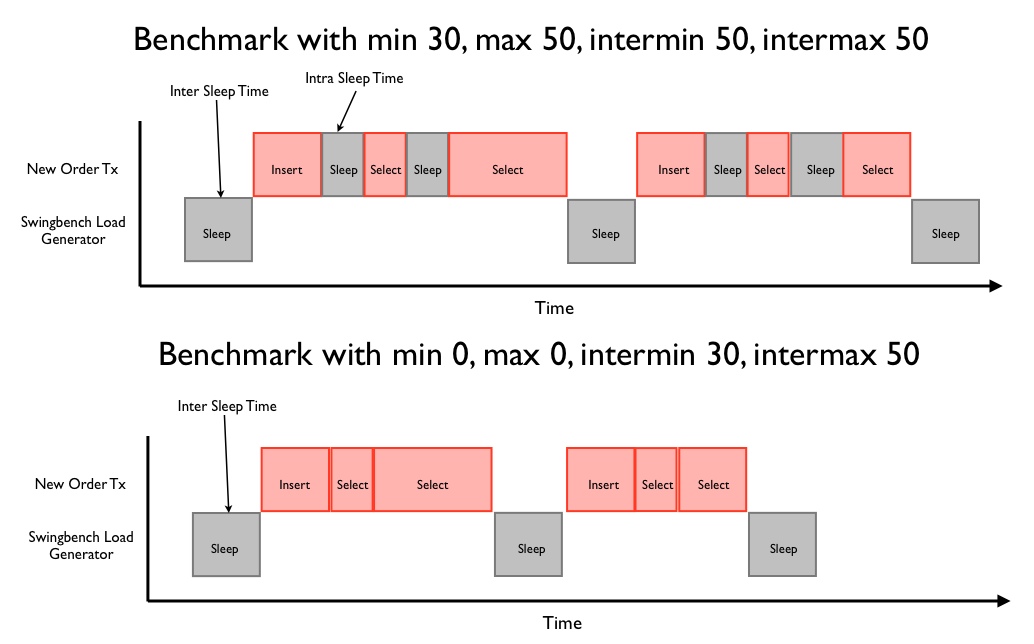
You can also set the intra and inter sleep time from the command line with the -min (intra min) -max (intramax) -intermin (inter min) -intermax (inter max).
In fixing some code I regressed some basic functionality. In the last build if you restarted a benchmark from within the swingbench and minibench GUI it gave you an error and you had to restart swingbench to get it going again. This is now fixed in this new build.
I also took the time to add some functionality to enable you to specify Inter and Intra sleep times. You can do this in the “Load” tab as shown below
It gives me the opportunity to explain the difference between inter and intra sleep times. As the name implies intra sleep times occur “inside” of a transaction. Inter sleep times occur between transactions. Many of the transactions inside of the swingbench “SOE” have sleep times between DML operations (select, insert, update). In some situations this better emulates what happens in some legacy form based systems, this is what is controlled by intra sleep times. However most systems these days tend to utilise web based front ends where DML operations tend to be fired as a single operation when the user submits a form. This approach results in a more scalable architecture with fewer locks being held and for shorter periods of time. Hopefully the following diagram will explain the differences in a clearer fashion.
You can also set the intra and inter sleep time from the command line with the -min (intra min) -max (intramax) -intermin (inter min) -intermax (inter max).
First Update to Swingbench 2.5
11/11/13 21:14 Filed in: Swingbench
Just a small update to swingbench... You can download the new build here
It fixes a few of bugs
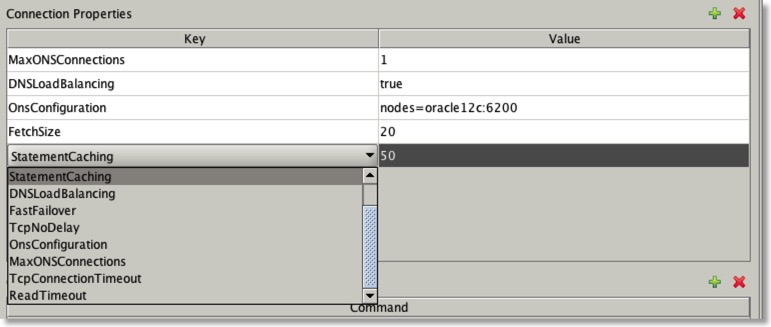
So the next obvious question is “What are all the connection properties and why did it take you so long to tell us?”. I have no idea why it took so long to tell people what they were. Consider it an over sight but let me try and correct that now.
It fixes a few of bugs
- Incorrect partitioning defaults specified in the oewizard and shwizards configuration files
- Incorrect profile of transactions for “sh” benchmark
- “sh” benchmark transaction generated queries for future values that didn’t exist
- Checks not performed on allowed partitioning values in configuration files for wizard when run in command line
So the next obvious question is “What are all the connection properties and why did it take you so long to tell us?”. I have no idea why it took so long to tell people what they were. Consider it an over sight but let me try and correct that now.
| Connection Properties | Description |
| StatementCaching | This specifies the number of statements to be cached. Valid value is an integer |
| DNSLoadBalancing | Force jdbc to connect to more than one scan listener. Valid values are true or false |
| FastFailover | Activate Oracle’s Fast Failover connection functionality. Valid values are true or false |
| TcpNoDelay | Sets TCP_NODELAY of a socket. Valid values are true or false |
| OnsConfiguration | The remote configurations of Oracle Notification Servers (ONS). Valid values are similar to this “nodes=dbserver1:6200,dbserver2:6200”. See Oracle documentation for more details and examples |
| MaxONSConfiguration | The number of ONS servers that jdbc will randomly select from in the advent of a failure. Valid value is an integer |
| TcpConnectionTimeout | The time taken between traversals of an “ADDRESS_LIST” in the advent of a failure. Specified in seconds |
| ReadTimeOut | The time queries wait for results before considering that a failure has occurred. Specified in seconds |
| BatchUpdates | The number of inserts/updates that are grouped together to improve transaction performance. Valid value is an integer |
| FetchSize | Number of rows fetched on each round trip to the database. Valid value is an integer |
Using the wizards in comand line mode
15/07/13 16:21 Filed in: Swingbench
I’ve just been reminded that not everybody knows that you can run swingbench in command line mode to use nearly all of it’s functionality. Whilst VNC means that you can use the graphical front end for most operations sometimes you need a little more flexibility. One area that this is particularly useful is when you’re creating large benchmark schemas for the SOE and SH benchmarks via the wizards (oewizard, shwizard). To find out what commands you can use just use the “-h” option. As you can see below there’s access to nearly all of the parameters (and a few more) that are available in the graphical user interface.
Using these parameters its possible to specify a complete install and drop operation from the command line. For example
This will create a 10 GB (Data) schema using 32 threads, use no partitioning and use the soe schema.
You can drop the same schema with the following command
I use this approach to create lots of schemas to automate some form of testing… The following enables me to create lots of schemas to analyse how the SOE benchmark performs as the size of the data set and index increase.
./oewizard -scale 5 -cs //oracle12c/orcl -dbap manager -ts SOE5 -tc 32 -nopart -u soe5 -p soe5 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe5.dbf
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE10 -tc 32 -nopart -u soe10 -p soe10 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe10.dbf
./oewizard -scale 20 -cs //oracle12c/orcl -dbap manager -ts SOE20 -tc 32 -nopart -u soe20 -p soe20 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe20.dbf
./oewizard -scale 40 -cs //oracle12c/orcl -dbap manager -ts SOE40 -tc 32 -nopart -u soe40 -p soe40 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe40.dbf
./oewizard -scale 80 -cs //oracle12c/orcl -dbap manager -ts SOE80 -tc 32 -nopart -u soe80 -p soe80 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe80.dbf
usage: parameters:
-allindexes build all indexes for schema
-bigfile use big file tablespaces
-cwizard config file
-cl run in character mode
-compositepart use a composite paritioning model if it exisits
-compress use default compression model if it exists
-create create benchmarks schema
-csconnectring for database
-dbadba username for schema creation
-dbappassword for schema creation
-debug turn on debugging output
-debugf turn on debugging output to file (debug.log)
-dfdatafile name used to create schema in
-drop drop benchmarks schema
-dtdriver type (oci|thin)
-g run in graphical mode (default)
-generate generate data for benchmark if available
-h,--help print this message
-hashpart use hash paritioning model if it exists
-hcccompress use HCC compression if it exisits
-nocompress don't use any database compression
-noindexes don't build any indexes for schema
-nopart don't use any database partitioning
-normalfile use normal file tablespaces
-oltpcompress use OLTP compression if it exisits
-ppassword for benchmark schema
-part use default paritioning model if it exists
-pkindexes only create primary keys for schema
-rangepart use a range paritioning model if it exisits
-s run in silent mode
-scalemulitiplier for default config
-spthe number of softparitions used. Defaults to cpu
count
-tcthe number of threads(parallelism) used to
generate data. Defaults to cpus*2
-tstablespace to create schema in
-uusername for benchmark schema
-v run in verbose mode when running from command
line
-versionversion of the benchmark to run
Using these parameters its possible to specify a complete install and drop operation from the command line. For example
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE -tc 32 -nopart -u soe -p soe -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe.dbf
This will create a 10 GB (Data) schema using 32 threads, use no partitioning and use the soe schema.
You can drop the same schema with the following command
./oewizard -scale 0.1 -cs //oracle12c/orcl -dbap manager -ts SOE -u soe -p soe -cl -drop
I use this approach to create lots of schemas to automate some form of testing… The following enables me to create lots of schemas to analyse how the SOE benchmark performs as the size of the data set and index increase.
./oewizard -scale 1 -cs //oracle12c/orcl -dbap manager -ts SOE1 -tc 32 -nopart -u soe1 -p soe1 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe1.dbf
./oewizard -scale 5 -cs //oracle12c/orcl -dbap manager -ts SOE5 -tc 32 -nopart -u soe5 -p soe5 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe5.dbf
./oewizard -scale 10 -cs //oracle12c/orcl -dbap manager -ts SOE10 -tc 32 -nopart -u soe10 -p soe10 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe10.dbf
./oewizard -scale 20 -cs //oracle12c/orcl -dbap manager -ts SOE20 -tc 32 -nopart -u soe20 -p soe20 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe20.dbf
./oewizard -scale 40 -cs //oracle12c/orcl -dbap manager -ts SOE40 -tc 32 -nopart -u soe40 -p soe40 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe40.dbf
./oewizard -scale 80 -cs //oracle12c/orcl -dbap manager -ts SOE80 -tc 32 -nopart -u soe80 -p soe80 -cl -df /home/oracle/app/oracle/oradata/ORCL/datafile/soe80.dbf