-
-
Should I use 2.6, 2.5, 2.4 or 2.3 of swingbench
At this point in time I’d recommend using Swingbench 2.6. It features Oracle Database 12c Release 2 and Oracle Database 18c support. Please use this version and let me know if you have any issues.
-
Is swingbench really free?
Yes. It comes as seen, there are no licenses or support charges. If you find it useful let us know.
-
Can I get support for swingbench?
No. There is no support mechanism for swingbench, it is not an official Oracle product (hence the reason for it being on my personal website). I'll fix obvious bugs but sadly my full time job does not allow me to provide advice on training or how to configure swingbench. I have started improving the documentation and rounding off some of the rough edges which should help.
-
How do I report a bug for Swingbench/TraceAnalyzer/DataGenerator?
Whilst no official system exisits for reporting bugs against swingbench you can email the problem directly to me via the
comments page and I'll do my very best to resolve the issue in one of the following point releases. When you report the bug can you please ensure that you include
- Swingbench version
- The platform swingbench is running on
- A description of the error
- Any debug out put that you think is releveant (In 2.3 try running with the -debug option)
-
Can I raise SRs against swingbench?
No. As I indicated above there is no official support channel for Swingbench. If its something you simply can't figure out leave me a message on
comments page and I'll get back to you as soon as I can. If there is enough interest I'll put together a forum or bug repository.
-
Can I get hold of the source code for swingbench?
No. Im not in a position to distribute the Swingbench kernel however I do distribute all of the source code for the transactions which can be viewed and modified. This is still my intellectual property and shouldn't be used with anything other than the Swingbench framework.
-
Can swingbench be used to benchmark hardware?
Whilst this is one of the main uses of Swingbench it has to be stated that because it is an unofficial product the author or Oracle Corporation will not offer an guarantees on the validity of the results. It should primarily be used as a guide line.
-
Can I run swingbench against databases other than Oracle
This is not the aim of Swingbench. It is designed as a support/demo tool of Oracle technology. We have no plans to extend its functionality to run against non Oracle databases. Currently it supports Oracle and TimesTen only.
-
Where can I find up to date info on swingbench
I try and update my thoughts on the development of swingbench and any minor changes I make inside of my blog which you can find it
here.
-
Can I change the transactions used by swingbench or include by own.
Yes. The source code for all of the transactions is included in the distribution. It can be found under the $SWINGHOME/source directory. An "ant" script is also shipped that easily compiles all of the source code for you. It is also possible to modify some simple PL/SQL packages to include your own code. This screen cast
describes all of the ways possible to modify swingbench.
-
Why hasn't there been a new release lately?
Developing swingbench is not my full time (or even part time) job. It is done to support projects inside of Oracle.
-
-
I'm struggling to get swingbench to work with 64bit OCI libraries I get " ELFCLASS64 (Possible cause: architecture word width mismatch)"
This is because swingbench boot straps another JVM. To fix this issue you need to edit the $SWINGHOME/launcher/launcher.xml file. Change the following section in the file
to
Also make sure you are pointing to the right version of the jdbcoci libraries.
-
What versions of jdbc do you use?
Swingbench ships with the current production jdbc drivers available from the Oracle website. It is possible to change these to older or newer versions by simply removing ons.jar,ucp.jar and ojdbc6.jar/odbc8.jar from the lib directory and replacing them with your preferred equivalents
-
How does cpumonitor work in 2.4/2.5/2.6?
The new functionality in 2.4/2.5/2.6 for monitoring System resources (Disk and CPU) uses Secure Shell for accessing the remote system
-
I get out of memory messages when running swingbench i.e. java.lang.OutOfMemoryError: Java heap space
This is caused by a variety of reasons. It might be caused because statistics are being collected over a long period of time. The amount of memory allocated to swingbench can be changed by editing the files responsible for launching the code.
In Swingbench version 2.4/2.5/2.6 You need to edit the launcher file. This file is located in the "launcher" directory and is called "launcher.xml". Simply edit the file and change the values to reflect your required memory requirements. You only need to change the section titled jvmargset i.e.
<jvmargset id="base.jvm.args">
<jvmarg line="-Xmx1024m"/>
<!--<jvmarg line="-verbose:gc"/>-->
<!--<jvmarg line="-Djava.util.logging.config.file=log.properties"/>-->
</jvmargset>
becomes (if your increasing the default memory used to 4GB)
<jvmargset id="base.jvm.args">
<jvmarg line="-Xmx4096m"/>
<!--<jvmarg line="-verbose:gc"/>-->
<!--<jvmarg line="-Djava.util.logging.config.file=log.properties"/>-->
</jvmargset>
-
How do I automate swingbench for testing
The easiest way to automate several runs of swingbench is by using charbench and command line options. This enables the scripting of several runs that can be run "lights out". An example of this might be something like
time ./oewizard -cl -create -scale 1 -u soe1 -p soe1 -ts soescale1 -tc 16 -s
./charbench -u soe1 -p soe1 -uc 100 -min 10 -max 200 -rt 0:10 -a -s -r scale1_100user.xml
./charbench -u soe1 -p soe1 -uc 200 -min 10 -max 200 -rt 0:10 -a -s -r scale1_200user.xml
./charbench -u soe1 -p soe1 -uc 300 -min 10 -max 200 -rt 0:10 -a -s -r scale1_300user.xml
time ./oewizard -cl -create -scale 10 -u soe10 -p soe10 -ts soescale10 -tc 16 -s
./charbench -u soe10 -p soe10 -uc 100 -min 10 -max 200 -rt 0:10 -a -s -r scale10_100user.xml
./charbench -u soe10 -p soe10 -uc 200 -min 10 -max 200 -rt 0:10 -a -s -r scale10_200user.xml
./charbench -u soe10 -p soe10 -uc 300 -min 10 -max 200 -rt 0:10 -a -s -r scale10_300user.xml
This example uses oewizard to create a schema "soe1" in a tablespace soescale1 using 16 threads to build it. It then runs 3 workloads against the schema increasing the user count for each run. It then builds a bigger schema (scale 10 = 32GB of space) and reruns the test.
-
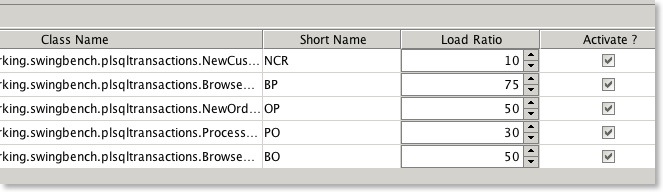
What does the transaction load ratio mean?
The load ratio is the ratio in comparison to other transactions. ie.
- T1 load ratio 10 = typically executes 16% of the time
- T2 load ratio 20 = typically executes 33% of the time
- T3 load ratio 30 = typically executes 50% of the time
Load ratios allow more precise control of the transactions. You change the ratios by modify the values within the config file or by changing them with the swingbench UI as shown below.
-
What is the maximum CPU load I should run a load generator at?
In theory the load generator(s) should be run on a seperate machine to the database and the average load should be kept below 70%. This generally results in reliable results
-
Whats the best version of swingbench to run my tests with?
Currently Im recommending 2.6.
-
How many load generators (servers) will it take to fully load a database server with?
It Depends. Typically it is a ratio of one load generator CPU to two database CPU's That is to say it would take a 2 CPU machine to fully load a 4 CPU machine. This assumption is based on the CPU’s/Cores being of equal processing power and the load being run with zero think time. It is usually the case that you will need as least 2-4 users/threads per CPU/Core.
-
Whats the difference between swingbench,minibench and charbench
Swingbench, minibench and charbench are simply frontends on the swingbench kernel. Swingbench is a rich fully functional frontend that includes several real time charts and as a result has a significant cpu cost associated with it. Minibench is a simple graphical tool without the overhead of Swingbench but is useful for users who like to be able to see what is happening in an organised and controlled fashion. Charbench is a character front end that enables the load generator to be be run where it is not possible/sensible to use a graphical front end. All three of the front ends have the same functionality and are interchangeable with one another.
-
I keep geeting a java exception "java.lang.NoSuchMethodError: oracle.jdbc.pool.OracleDataSource". What am I doing wrong.
Swingbench require's the latest versions of jdbc to work properly. Download the 12c jdbc drivers from Oracle and use these even when running against older versions of the database database.
-
Can I run mulitiple load generators against a single database instance?
Yes. In fact it is advisable when running a large load against a database to use multiple copies of swingbench. These can be coordinated using clusteroverview.
-
Is there a walkthough available for clusteroverview in 2.3 and 2.4
Yes it can be found
here.
-
Which JVM should I use?
Swingbench is always complied and tested with the latest version of the JVM. Currently the only supported VM is the Oracle Java VM : Java 8
-
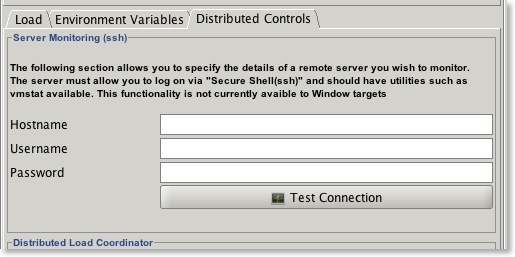
How do I get CPU monitoring working?
To configure it simply go to the Distributed Controls tab and enter the hostname of a server you wish to monitor. The username and password should be of a user who can run vmstat. You can test the connection with the button to highlight any security issues.
-
Why don't I see CPU and disk statistics inside of swingbench when running on the Windows platform?
The CPU/Disk monitor used by swingbench uses the common unix utility vmstat to calculate the load on a target platform. This utility is not availble by default for Windows however it can be obtained via the Cygwin environment (www.cygwin.com). Currently Solaris only reports CPU and AIX dosen't report either statistic. This is being fixed
-
I don't get any charts, other than user count, inside of clusteroverview, what have I broken?
This usually occurs because the the "DisplayName" in clusteroverview.xml is different to the connect string being used by a load generator. Presently if you wish to measure the scalability of a cluster the DisplayName attribute must match one or more load generators connect strings. i.e if you have a load generator(s) with a connect string of //node1:1521/soeservice the DisplayName must be //node1:1521/soeservice.
-
How do I modify or rename supplied benchmark transactions
Whilst this isn't the place to show you how to develop swingbench transactions in java I can show you basic steps to modify or rename the supplied benchmark transactions.
You might want to do this if you wanted to develop your own code, add more transactions or simply call them something else.
You do this with a few simple steps (The following assumes that swingbench is installed in your home directory)
1/ change directory into the base swingbench source directory
i.e.
cd ~/swingbench/source/com/dom/benchmarking/swingbench
2/ take a copy of one of the directories
cp -r storedprocedures/ newtransactions
3/ cd into the new directory
cd newtransactions/
4/ Delete all but one of the transactions (it will save a little time later)
rm StoredProcedure[23456].java
5/ Rename the transaction to your preferred name
mv StoredProcedure1.java TopPerformers.java
6/ Edit the java file to reflect the name change
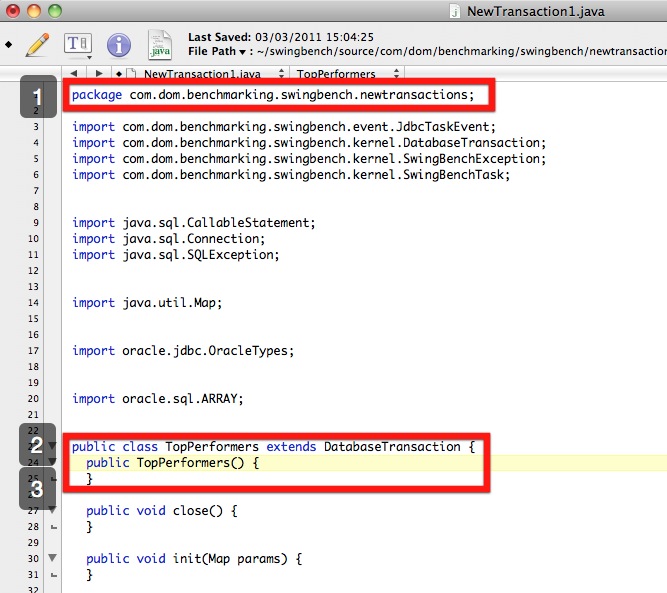
The first change reflects the new package name. The second and reflects the new name of the transaction you are creating.
7/ repeat step 5 and 6 for all of the transactions you wish to create. You might at this stage also modify the code to reflect any other functionality changes you want to make.
8/ change directory to the main swingbench source directory
i.e.
cd ~/swingbench/source
9/ run ant to compile the code (it will use the build.xml file in the source directory). You'll need to make sure that java is in your path etc.
$ ant
Buildfile: /Users/dgiles/swingbench/source/build.xml
clean:
init:
[echo] Building file /Users/dgiles/swingbench/lib/mytransactions.jar from the directory /Users/dgiles/swingbench
[mkdir] Created dir: /Users/dgiles/swingbench/classes
compile:
[javac] /Users/dgiles/swingbench/source/build.xml:19: warning: 'includeantruntime' was not set, defaulting to build.sysclasspath=last; set to false for repeatable builds
[javac] Compiling 44 source files to /Users/dgiles/swingbench/classes
[javac] Note: Some input files use unchecked or unsafe operations.
[javac] Note: Recompile with -Xlint:unchecked for details.
dist:
[jar] Building jar: /Users/dgiles/swingbench/lib/mytransactions.jar
[delete] Deleting directory /Users/dgiles/swingbench/classes
BUILD SUCCESSFUL
Total time: 1 second
10/ The step above will not only compile the code but build a "jar" file and copy it into your swingbench/lib directory. The next step will be to use the transactions inside of swingbench. To do this simply make a copy of the default swingbench config file and edit this
$ cd ../bin
$ cp swingconfig.xml newtransactions.xml
$ edit newtransactions.xml
11/ Edit the config file to reflect the work carried out in the previous steps
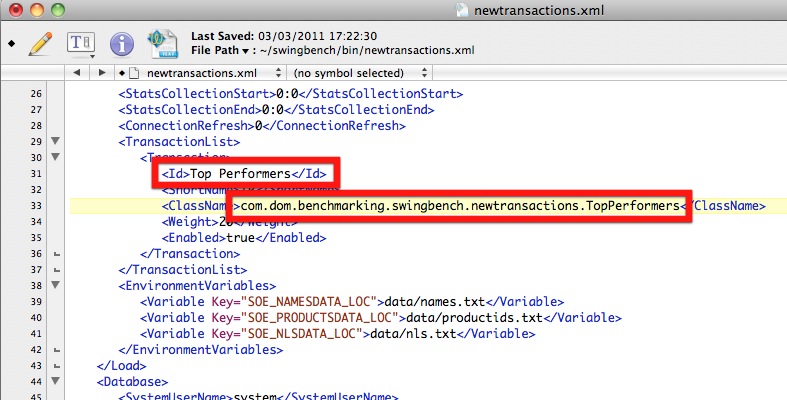
12/ Save the file and start swingbench using the new configuration
i.e.
$ ./swingbench -c newtransactions.xml
And thats it.
-
How do I control the number of users logging on to prevent log on storms
Whilst Oracle deals very well with large numbers of users logging on at the same time some approaches, such as connection pooling, depend on the gradual logging on of users to work efficiently. Swingbench mimics this effect by logging users on in batches and enabling to begin their transactions as soon as they've logged on. To define your log on profile you'll need to enter values in the "Load" section. In the example below we've asked swingbench to log users on in batches of 10 every second and by specifying "Wait Till All Session Log On" to false swingbench will allow the session to begin running their transactions as soon as they've successfully connected. This means that for the example below it will take 50 seconds to load all of the users on and transactions will begin immediately.
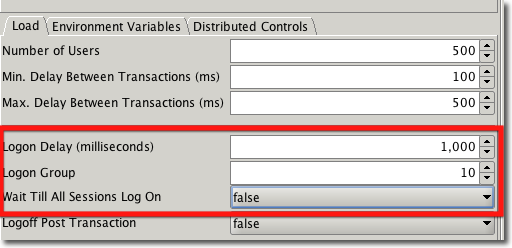
The profile you use will depend entirely on the number of sessions to be logged on and the processing they will do when logged on. Most systems don't logon 10,000 sessions straight onto their server first thing in the morning. It is likely to be a steady increase over a period of time. Logging users on whilst transactions are being processed is a good test of the network and power of your server.
-
Can I set various connection properties i.e. "Statement Caching"
Yes. From Swingbench 2.5 you can set connection properties via a set of drop down lists in the connection properties dialogue.
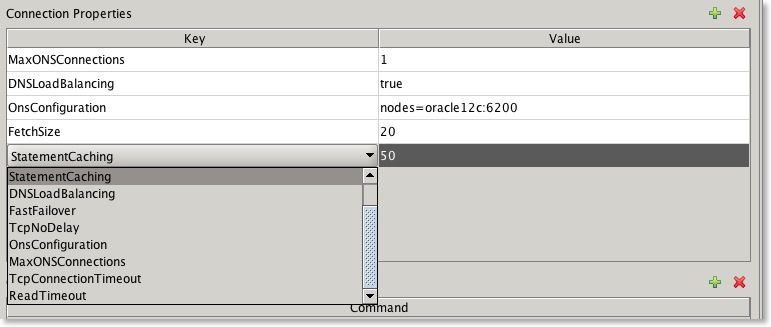
The following table describe valid connection properties.
Connection Properties
| Description
|
StatementCaching
| This specifies the number of statements to be cached. Valid value is an integer
|
DNSLoadBalancing
| Force jdbc to connect to more than one scan listener. Valid values are true or false
|
FastFailover
| Activate Oracle’s Fast Failover connection functionality. Valid values are true or false
|
TcpNoDelay
| Sets TCP_NODELAY of a socket. Valid values are true or false
|
OnsConfiguration
| The remote configurations of Oracle Notification Servers (ONS). Valid values are similar to this “nodes=dbserver1:6200,dbserver2:6200”. See Oracle documentation for more details and examples
|
MaxONSConfiguration
| The number of ONS servers that jdbc will randomly select from in the advent of a failure. Valid value is an integer
|
TcpConnectionTimeout
| The time taken between traversals of an “ADDRESS_LIST” in the advent of a failure. Specified in seconds
|
ReadTimeOut
| The time queries wait for results before considering that a failure has occurred. Specified in seconds
|
BatchUpdates
| The number of inserts/updates that are grouped together to improve transaction performance. Valid value is an integer
|
FetchSize
| Number of rows fetched on each round trip to the database. Valid value is an integer
|
-
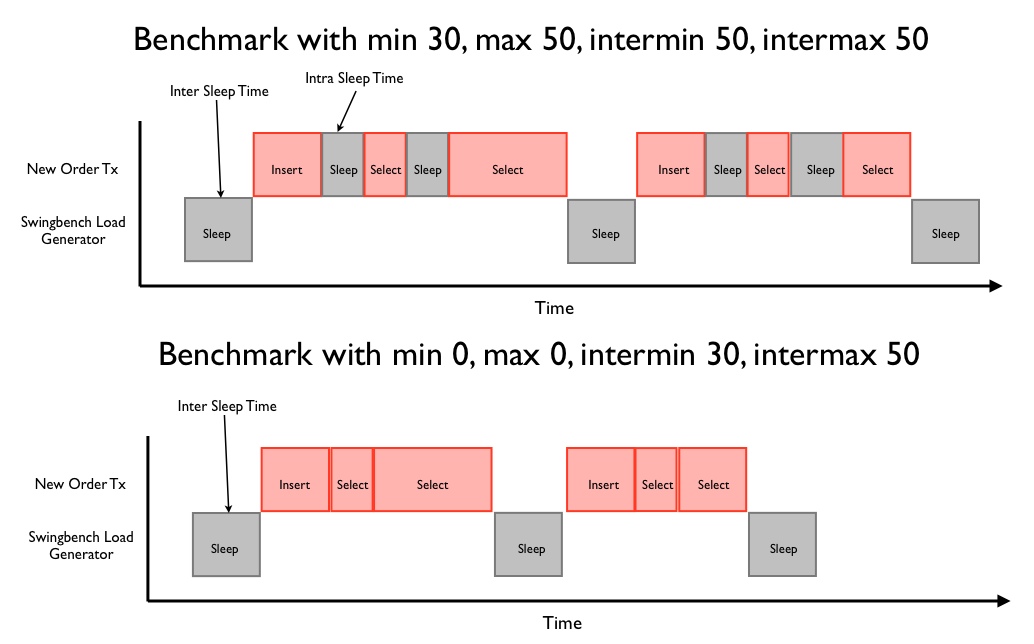
Whats the difference between "inter" and "intra" sleep times in swingbench?
As the name implies intra sleep times occur “inside” of a transaction. Inter sleep times occur between transactions. Many of the transactions inside of the swingbench “SOE” have sleep times between DML operations (select, insert, update). In some situations this better emulates what happens in some legacy form based systems, this is what is controlled by intra sleep times. However most systems these days tend to utilise web based front ends where DML operations tend to be fired as a single operation when the user submits a form. This approach results in a more scalable architecture with fewer locks being held and for shorter periods of time. Hopefully the following diagram will explain the differences in a clearer fashion.
You can set inter and intra sleep times in the "Load" tab of the swingbench GUI as shown below
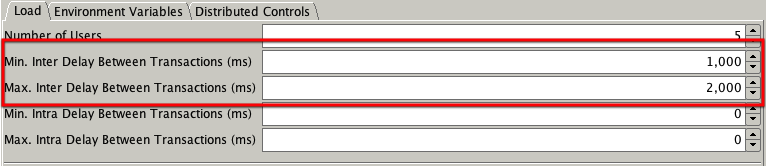
You can also set the intra and inter sleep time from the command line with the -min (intra min) -max (intramax) -intermin (inter min) -intermax (inter max).
-
-
How can I tell if the benchmark has installed correctly?
In 2.4/2.5/2,6 of swingbench the wizard will check whether the schema has the right number of tables/indexes/procedures etc. At the end of the install it will display a small report providing details of the run time and a list of invalid and valid objects (see below). All of the objects that have been created should be valid.
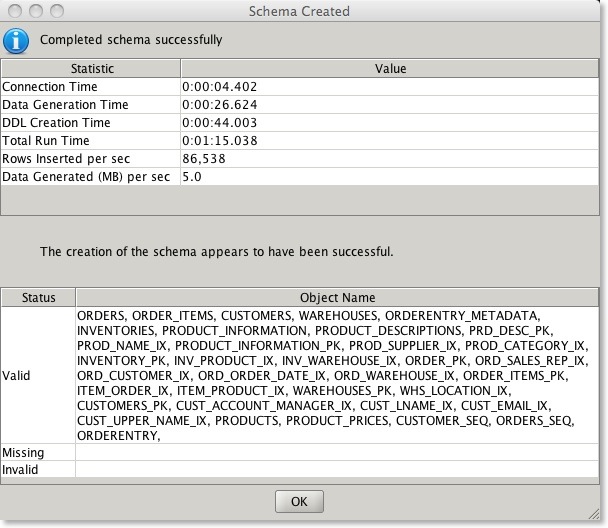
It’s also possible to validate the benchmark after installation using the SBUtil. Currently this can be done by using a command such as
$ ./sbutil -soe -u soe -p soe -cs //ora18server/soe -val
The Order Entry Schema appears to be valid.
--------------------------------------------------
|Object Type | Valid| Invalid| Missing|
--------------------------------------------------
|Table | 10| 0| 0|
|Index | 26| 0| 0|
|Sequence | 5| 0| 0|
|View | 2| 0| 0|
|Code | 1| 0| 0|
--------------------------------------------------
replacing the username, password and connect string with your own. You will need to specify either -soe, -sh or -tpcds to indicate which benchmark schema you are working with.
-
I get warnings during the build of a benchmark
This may be perfectly normal. They may occur if the scripts attempt to drop objects that don't exist. Check their context and the final report to see if all of the objects are valid.
-
What should the SOE benchmark look like on completition
You should have the following tables and and index count. You can check this the sbutil command.
Ignore the row counts these will depend on the size of the benchmark you selected.
$> ./sbutil -soe -u soe -p soe -cs //ora18server/soe -tables
Order Entry Schemas Tables
----------------------------------------------------------------------------------------------------------------------
|Table Name | Rows| Blocks| Size| Compressed?| Partitioned?|
----------------------------------------------------------------------------------------------------------------------
|INVENTORIES | 895,752| 22,216| 175.0MB| Disabled| No|
|ORDER_ITEMS | 2,261,863| 15,331| 121.0MB| Disabled| No|
|ORDERS | 771,761| 10,358| 82.0MB| Disabled| No|
|CUSTOMERS | 337,669| 5,668| 45.0MB| Disabled| No|
|ADDRESSES | 389,525| 4,534| 36.0MB| Disabled| No|
|LOGON | 1,013,791| 3,526| 28.0MB| Disabled| No|
|CARD_DETAILS | 387,669| 2,770| 22.0MB| Disabled| No|
|WAREHOUSES | 1,000| 124| 1024KB| Disabled| No|
|ORDERENTRY_METADATA | 4| 124| 1024KB| Disabled| No|
|PRODUCT_INFORMATION | 1,000| 124| 1024KB| Disabled| No|
|PRODUCT_DESCRIPTIONS | 1,000| 124| 1024KB| Disabled| No|
----------------------------------------------------------------------------------------------------------------------
Total Space 513.0MB
$> ./sbutil -soe -u soe -p soe -cs //ora18server/soe -indexes
Order Entry Schemas Indexes
---------------------------------------------------------------------------------------------------------------------------------------------------------
|Table Name |Index Name |Indexed Columns | Size| Status| Levels| Partitioned?| Compression|
---------------------------------------------------------------------------------------------------------------------------------------------------------
|ADDRESSES |ADDRESS_PK |ADDRESS_ID | 20.0MB| Valid| 2| No| Disabled|
|ADDRESSES |ADDRESS_CUST_IX |CUSTOMER_ID | 20.0MB| Valid| 2| No| Disabled|
|CARD_DETAILS |CARD_DETAILS_PK |CARD_ID | 20.0MB| Valid| 2| No| Disabled|
|CARD_DETAILS |CARDDETAILS_CUST_IX |CUSTOMER_ID | 20.0MB| Valid| 2| No| Disabled|
|CUSTOMERS |CUST_FUNC_LOWER_NAME_IX |SYS_NC00017$,SYS_NC00018$ | 20.0MB| Valid| 2| No| Disabled|
|CUSTOMERS |CUST_EMAIL_IX |CUST_EMAIL | 20.0MB| Valid| 2| No| Disabled|
|CUSTOMERS |CUST_DOB_IX |DOB | 20.0MB| Valid| 2| No| Disabled|
|CUSTOMERS |CUST_ACCOUNT_MANAGER_IX |ACCOUNT_MGR_ID | 20.0MB| Valid| 2| No| Disabled|
|CUSTOMERS |CUSTOMERS_PK |CUSTOMER_ID | 20.0MB| Valid| 2| No| Disabled|
|INVENTORIES |INV_WAREHOUSE_IX |WAREHOUSE_ID | 20.0MB| Valid| 2| No| Disabled|
|INVENTORIES |INV_PRODUCT_IX |PRODUCT_ID | 20.0MB| Valid| 2| No| Disabled|
|INVENTORIES |INVENTORY_PK |PRODUCT_ID,WAREHOUSE_ID | 18.0MB| Valid| 2| No| Disabled|
|ORDERS |ORD_WAREHOUSE_IX |WAREHOUSE_ID,ORDER_STATUS | 20.0MB| Valid| 2| No| Disabled|
|ORDERS |ORD_SALES_REP_IX |SALES_REP_ID | 20.0MB| Valid| 1| No| Disabled|
|ORDERS |ORD_ORDER_DATE_IX |ORDER_DATE | 27.0MB| Valid| 2| No| Disabled|
|ORDERS |ORD_CUSTOMER_IX |CUSTOMER_ID | 20.0MB| Valid| 2| No| Disabled|
|ORDERS |ORDER_PK |ORDER_ID | 20.0MB| Valid| 2| No| Disabled|
|ORDER_ITEMS |ORDER_ITEMS_PK |ORDER_ID,LINE_ITEM_ID | 68.0MB| Valid| 2| No| Disabled|
|ORDER_ITEMS |ITEM_PRODUCT_IX |PRODUCT_ID | 61.0MB| Valid| 2| No| Disabled|
|ORDER_ITEMS |ITEM_ORDER_IX |ORDER_ID | 60.0MB| Valid| 2| No| Disabled|
|PRODUCT_DESCRIPTIONS |PROD_NAME_IX |TRANSLATED_NAME | 1024KB| Valid| 1| No| Disabled|
|PRODUCT_DESCRIPTIONS |PRD_DESC_PK |PRODUCT_ID,LANGUAGE_ID | 1024KB| Valid| 1| No| Disabled|
|PRODUCT_INFORMATION |PROD_SUPPLIER_IX |SUPPLIER_ID | 1024KB| Valid| 1| No| Disabled|
|PRODUCT_INFORMATION |PROD_CATEGORY_IX |CATEGORY_ID | 1024KB| Valid| 1| No| Disabled|
|PRODUCT_INFORMATION |PRODUCT_INFORMATION_PK |PRODUCT_ID | 1024KB| Valid| 1| No| Disabled|
|WAREHOUSES |WHS_LOCATION_IX |LOCATION_ID | 1024KB| Valid| 1| No| Disabled|
|WAREHOUSES |WAREHOUSES_PK |WAREHOUSE_ID | 1024KB| Valid| 1| No| Disabled|
---------------------------------------------------------------------------------------------------------------------------------------------------------
Total Space 541.0MB
-
I don't appear to have the right number of indexes
This is probably because you either ran out of space or you didn't size your TEMP correctly. As a guide line for a schema of size “x” you'll need at least “x/6” worth of temp space i.e. 1TB schema needs about 180GB of temp. You can resize it after the build to what ever you decide is appropriate.
-
Nothing happens for ages when I start the SOE benchmark
If you've created a large schema make sure you've set the SOE_MIN_CUSTOMER_|D and SOE_MAX_CUSTOMER_ID environment variables. To set them follow the instructions below or edit the config file
Select the Environment Variables tab and press the

button (you’ll need to do this for each environment variable).

Add two Enviroment variables
- SOE_MIN_CUSTOMER_ID : The value equals the smallest customer id in the data set, usually 1
- SOE_MAX_CUSTOMER_ID : The largerst customer id found in the data set
You can determine what thes values are by running a piece of SQL similar to this when logged into the SOE schema
SELECT
/*+ PARALLEL(CUSTOMERS, 8) */
MIN(customer_id) SOE_MIN_CUSTOMER_ID,
MAX(customer_id) SOE_MAX_CUSTOMER_ID
FROM customers
After adding the variables you should end up with something that looks similar to this
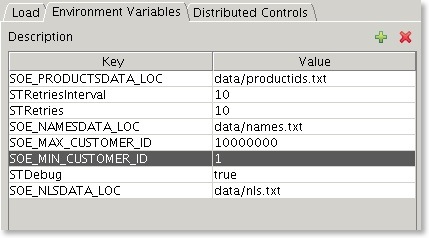
-
The benchmark isn't running as quickly as I thought it would.
That's not unexpected. Some features of the benchmarks are designed to introduce a degree of contention to determine how well the underlying hardware handles it. It is unlikely you will be able to get the CPU to run at 100% especially as you increase the size of the schema. Use the AWR reports to determine what the issue is. Swingbench 2.3 enables you to take database snapshots at the start and end to determine the cause of wait event. You can enable this using the relevant fields within swingbench (shown in the image below). This will take a database snap at the start and end of the benchmark. Get your friendly tuning guru to take a look and make some recommendations.
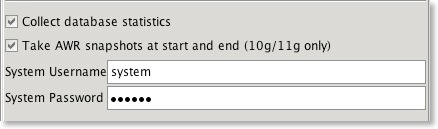
I also put the top ten wait events and their percentages into the output report (output tab in swingbench, results.xml in minibench and charbench) if the "Collect database statistics" option is checked. They should look something like this.
<DatabaseWaitEvents>
<DatabaseWaitEvent name="CPU Time" noOfTimesWaited="1" timeWaited="4729" percentageTimeWaited="51.26"/>
<DatabaseWaitEvent name="log file sync" noOfTimesWaited="32230" timeWaited="1950" percentageTimeWaited="21.14"/>
<DatabaseWaitEvent name="log file parallel write" noOfTimesWaited="48457" timeWaited="1247" percentageTimeWaited="13.52"/>
<DatabaseWaitEvent name="cell single block physical read" noOfTimesWaited="1012" timeWaited="567" percentageTimeWaited="6.15"/>
<DatabaseWaitEvent name="db file parallel write" noOfTimesWaited="7320" timeWaited="566" percentageTimeWaited="6.13"/>
<DatabaseWaitEvent name="control file sequential read" noOfTimesWaited="372" timeWaited="30" percentageTimeWaited="0.33"/>
<DatabaseWaitEvent name="reliable message" noOfTimesWaited="1" timeWaited="22" percentageTimeWaited="0.24"/>
<DatabaseWaitEvent name="gc cr grant 2-way" noOfTimesWaited="617" timeWaited="19" percentageTimeWaited="0.21"/>
<DatabaseWaitEvent name="buffer busy waits" noOfTimesWaited="1182" timeWaited="16" percentageTimeWaited="0.17"/>
<DatabaseWaitEvent name="ges message buffer allocation" noOfTimesWaited="98591" timeWaited="12" percentageTimeWaited="0.13"/>
<DatabaseWaitEvent name="SQL*Net message to client" noOfTimesWaited="44031" timeWaited="11" percentageTimeWaited="0.12"/>
</DatabaseWaitEvents>
-
Why do I need to keep generating new sets of data for each Callingcircle benchmark run?
NOTE : The Calling benchmark is deprecated. Modern CPU’s simply burn through the transactions too quickly and. I’ll keep it round for backwards compatibility but I won’t actively test or maintain it.
Callingcircle transactions are based on "customers" that need to be processed or have their details updated. The generation process looks for likely candidates and writes them to files. Each benchmark run updates customer details and so new candidates need to be found. Eventually a significant proportion of available customers have had their details updated and so the entire benchmark needs to be updated. It is also important that if you are using multiple load generators each has its own set of generated data.
-
How many transactions do I need to generate for a Callingcirle benchmark run?
It depends. The more powerful the machine/cluster the faster the transactions will be processed. A thousand transactions lasts only three minutes on a Xeon processor. Therefore to generate a 30 minute load you'd need at least 10,000 transactions and probably 40,000 transactions for a 4 CPU machine.
Update : I've been informed of an issue where its not possible to hold all of the transactions in memory for a long sustained run on a powerful machine. Im working on a solution to enable a disk based loading mechanism.
-
Why are there two versions of the Order Entry benchmark, client side and server side?
One uses PL/SQL stored procedures to generate a load and the other uses discrete java routines and individual jdbc statements, as a result the later will generate a lot of network traffic. We would recommend the use of the PL/SQL version of the benchmark.
-
Order Entry dosen't appear to scale as well as Callingcircle, why?
Order Entry updates a relatively small table containing stock levels at each warehouse. This creates a great deal of contention and limits it scalability.
-
Whats the difference between the Callingcircle benchmark and Order Entry benchmark?
Order entry models the classic order entry stress test. It has a similar profile to the TPC-C benchmark. This version models a online order entry system with users being required to log-on before purchasing goods. The Calling Circle benchmark represents a self-service OLTP application. The application models the customers of a telecommunications company registering, updating and inquiring on a calling circle of their most frequently called numbers in order to receive discounted call pricing. It is characterised by large amounts of dynamic PL/SQL and is CPU intensive. Calling Circle also requires the regeneration of data after each run.
-
What are the new transactions in the orderentry benchmark
I've included three additional transactions in the orderentry benchmark to enable users to increase the "Read" workload for the Oracle database.

The transactions are disabled by default and so won't effect any historical comparisons. To enable them for a benchmark run simply check the box on the right hand side of the table.
-
Is there a datawarehousing benchmark available?
Since Swingbench 2.3 the "shwizard" can be used to create a sales history schema. Swingbench also includes a config (shconfig under the $SWINGHOME/configs directory) with and a number of queries to stress the resultant schema.
Swinbench 2.6 also ships with a TPC-DS like benchmark.