Scaling Data
The key use of datagenerator is to scale up a schema. This enables users to determine how hardware will react when production data is increased in volume. The amount of data generated can be changed by either modifying the number of rows in each table or doing this automatically with the command line scaling option.
In this example we’ll use the graphical front end to demonstrate how simple this is. Other examples describe how to create very large datasets for swingbench.
Start datagenerator in either the bin directory (for Unix/Linux flavours) or in the winbin directory (for Windows). By sepecifying the -c command line option you can select a config file. if the following example we’ll select the soe.xml as a dataset we wish to increase in size.
$> ./datagenerator -c soe.xml
This will launch the following screen
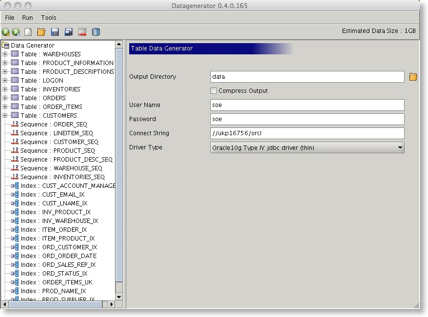
The estimated size of the default configuration is 1GB in size. NOTE : This is for the raw data and the indexes will in this instance take almost twice as much space as the raw data.
To increase the size of the schema select the
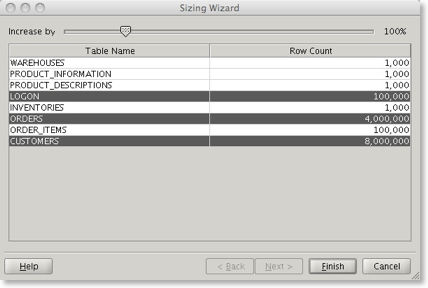
Windows that have been identifed as scalable will be automatically highlighted. Moving the slider along will increase the number of rows. The scale is logarithmic and will increase the size of the data set exponentially. In the following example I’ve increased the dataset by ten times.
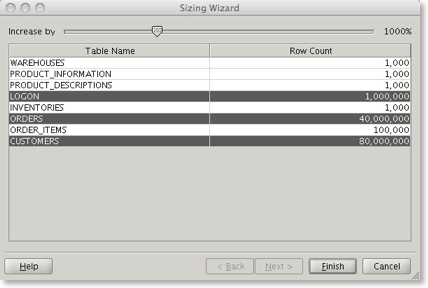
Pressing finish returns to the main screen and shows and updated estimated size.
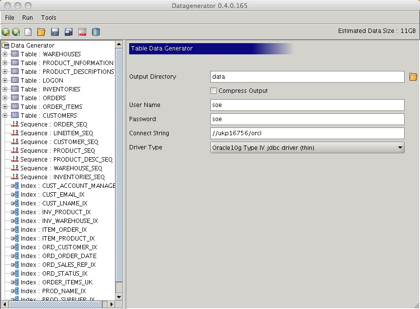
In this instance its now approximately 11GB in size.
For machines with large CPU counts it may also make sense to increase the number of soft parttions (threads) per table. This can significantly increase the overall throughput. To do this select and table, in this case orders, and use the soft partition spinner to increase the count.

The recomendation would be directly in line with the number of CPUs. For a 16 core server increase this to 16. At some stage in the future this number is likely to be driven be the overall level of parallelism.
To start the data generation select either the
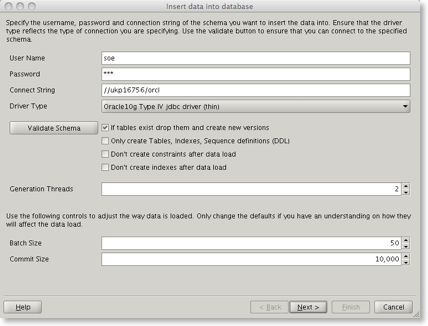
We are given a number of options. We can choose the default which will drop any tables if they exist generate the data, create indexes and any constraints. We can also change the default batch and commit size. On the whole the defaults are usually acceptable. By pressing next the data generation begins. It will lauch a window similar to this
The generation may continue for some time.